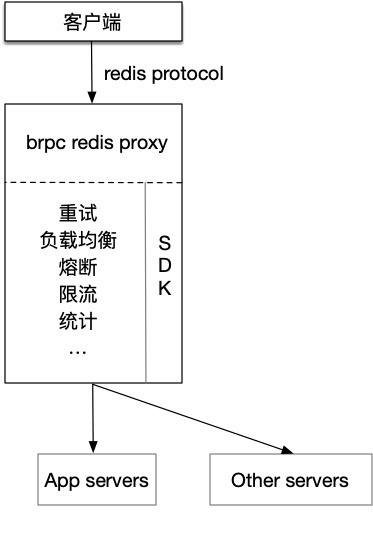
至于这个体验是好是坏,很多时候并不由我们自己决定。我是在欧洲的第二波疫情还没有爆发的时候过来的,此时每天新增的数字还在有效的控制范围中,还幻想着欧洲的疫情终于缓下来了,之后可以恢复正常的生活。结果后来我们都知道了,欧洲迎来了第二波猛烈的爆发,并且一直持续到了现在,也打破了我一周偶尔可以去办公室的节奏,瑞士疫情也更严重了,又进入了全面WFH(work from home)的阶段。对于我而言,这无疑是一个坏消息,一部分同事还没有线下见过面,这段时间的WFH经历告诉我,人是需要线下见面的,这样信任感才能慢慢建立起来,这也是对所有新入职同事的挑战和困难。
说到心态,我慢慢意识到人生很大程度上是一个心态游戏。人是一个喜欢做自我批判的动物,类似的想法比如「这件事我是做不好的」,「别人一定会觉得我这件事做得很差劲」、「别人背地里一定是在嘲笑我的」经常出现在人们的心中,变成自己进步和做事的阻碍。结合我自己的经验我想说得是,首先这些都不是真的,都是一些主观扭曲化后的想法,完全和现实违背;其次,不用在乎别人是怎么想的,无论你做得好做得差,总有人议论你。耐心地做好自己的事情,从小事慢慢积累自信。If you want to win like a champion, you have to think like a champion.
自己也慢慢放弃了对「确定性」这件事的执著,以前总是希望做事之前要有明确计划,要知道自己在干什么,而过去一整年的经历劈头盖脸地告诉我们,力所能及地做计划,做好当下的事才是最重要,至于未来怎么样,除了随机应变很难想到别的方法。我们都是在迷雾中行走,没有指南针没有地图,唯一能做的是摸索前进的同时,照顾好自己以及身边的人,thrive in ambiguity。
如果来了一个超紧急功能,我更倾向于的做法是好好评估一下,加下班做好代码抽象,而不是先粗糙实现然后加个TODO: refine this code,大部分情况下就渐渐就忘记了,变成以后的技术债了,更何况通常也不会有这种“今天开发明天上线”的需求。从软件开发的一开始就要保证每一次代码CheckIn都是高质量的,做好规范,一次写烂了就会发生第二次,然后慢慢地整个项目里都是烂代码,这就是破窗效应。在过去几年我C++写的比较多,以前有一段时间以为,功能本身的实现是需要关注的东西,而现在的观点是功能本身实现是开发中最基础最简单的东西,难的是代码抽象、性能压榨和对象的生命周期管理。另外不能偷懒,该重构的地方就立刻去重构,目的是降低代码的复杂度。让代码易维护的核心在于降低复杂度,这是一个很大的topic,推荐看《代码大全2》,最好的一本讲如何写好代码的书。
A classic paper on how different locking alternatives do and don’t scale: “The Performance of Spin Lock Alternatives for Shared-Memory Multiprocessors”↩
context switch的开销不仅仅是push和pop寄存器,它还引发了cache、TLB、branch predictor等CPU状态的丢失,具体如何测量CS的值,请参考“lmbench: Portable tools for performance analysis”↩
第一次接触抽象是我大学低年级学数据结构的时候,记得很清楚当时学一个概念叫抽象数据类型(abstract data type),大概意思就是一个数据结构,接口是一回事,实现是另一回事,比如栈,作为使用者你只需要知道它有push、pop、isEmpty等方法,但它的底层实现到底是array还是linked list,你是不需要知道的。
再往下一层,ISA(Instruction set architecture),俗称软件与硬件的接口。这个俗称是非常形象的。指令集架构,说得简单点就是机器码,也可以理解为一个协议。ISA标准制定者指定一套指令集(比如x86、PowerPC、SPARC),然后编译器开发者需要根据这个标准/协议来编写对应的编译器;CPU制造商需要根据这个标准/协议来制造出支持这套ISA的CPU(比如intel的CPU支持x86/x86_64)。也就是说,软件/硬件都依照这个ISA来设计,那么就可以对接了。
while(1){/* Wait for a connection, then accept() it */if((conn_s=accept(list_s,NULL,NULL))<0){fprintf(stderr,"ECHOSERV: Error calling accept()\n");exit(EXIT_FAILURE);}/* Retrieve an input line from the connected socket then simply write it back to the same socket. */Readline(conn_s,buffer,MAX_LINE-1);Writeline(conn_s,buffer,strlen(buffer));/* Close the connected socket */if(close(conn_s)<0){fprintf(stderr,"ECHOSERV: Error calling close()\n");exit(EXIT_FAILURE);}}
/* Main loop */while(1){structsockaddr_intheir_addr;size_tsize=sizeof(structsockaddr_in);intnewsock=accept(listenfd,(structsockaddr*)&their_addr,&size);intpid;if(newsock==-1){perror("accept");return0;}pid=fork();if(pid==0){/* In child process */close(listenfd);handle(newsock);return0;}else{/* Parent process */if(pid==-1){perror("fork");return1;}else{close(newsock);}}}
我自己的理解:信号之于进程,就好比中断之于CPU,是一种信息传递的方式。官方的解释是A signal is an asynchronous notification sent to a process or to a specific thread within the same process in order to notify it of an event that occurred.
一个程序在运行的时候,你可以发各种信号给这个进程,进程对这个信号做出响应。比如你发个SIGKILL给一个进程,该进程就知道用户要杀死它,然后就会终止进程。
一个更常见的例子,你在终端运行一个进程以后,如果是非后台进程,它会在console输出一些log,这时候shell也不能接受输入了,这时候你按下control+c,进程就被终止了,在这个过程中你就给这个进程发送了一个信号(SIGINT,interrupt signal),在默认情况下,是终止改进程。
那什么时候是非默认情况呢?这里需要引入信号处理器(signal handler)的概念,你可以为一部分信号编写特定的处理函数,比如在默认情况下,SIGINT是结束进程,你可以修改这个默认行为使它什么都不做(即一个空函数),但是有些信号的行为是无法修改的,比如SIGKILL。